

ARES is an open-source, RL-first framework for training coding agents with true online reinforcement learning. It treats the LLM itself as the policy, supports massively parallel async rollouts, and ships with tens of thousands of verifiable coding tasks (including SWE-Bench Verified). The goal is to enable real exploration and fast feedback—unlocking stronger coding agents than batch-style LLM RL allows.
Today we're open-sourcing ARES, the Agentic Research and Evaluation Suite—infrastructure for training coding agents with online reinforcement learning.
The big labs are betting that Reinforcement Learning (RL) will unlock superhuman coding. But their infrastructure is closed, and open-source tooling doesn't support true online RL. ARES closes that gap.
Why online RL?
Pre-LLM reinforcement learning breakthroughs (Go, StarCraft, robotics) followed a common recipe: highly parallel simulation plus online learning. The agent learns from states it actually reaches, not a static dataset. The policy improves, generates new data from that improved policy, improves again. Continuously.
Coding fits this regime. You can spin up thousands of sandboxes in parallel. Environments reset cleanly. Success is verifiable via tests. Yet almost no one is doing online RL on LLM agents.
Most LLM RL today is RL in notation only:
- Generate a batch of trajectories
- Score them
- Update the model
- Repeat
This works for refining existing capabilities. But the slow feedback loop limits exploration. Heavy KL regularization keeps the model close to its starting point. You're mostly reweighting outputs the model already produces, not discovering new behaviors. Recent work has shown this empirically: a NeurIPS 2025 paper found that current RL methods on LLMs don't elicit fundamentally new reasoning patterns; the reasoning paths generated by RL-trained models already exist in the base model's distribution.
Here's the problem in concrete terms: suppose your model learns a subtle bad habit during training—say, a tendency to overwrite config files rather than append to them. In batch RL, you won't discover this until you score the next batch, by which point you've already reinforced the behavior across thousands of updates. In online RL, the negative signal shows up as soon as any rollout hits the failure mode, and the model corrects course immediately.
This matters for long-horizon, sparse-reward problems where agents must explore, fail, and recover. Coding agents navigating large codebases, recovering from architectural mistakes, solving novel problems—this is exactly that kind of problem.
What is ARES?
ARES is a Gym-like framework, modernized for LLM agents and high-throughput remote execution. We designed it specifically around code agents. Three design choices define it:
1. The LLM is the agent, not the scaffolding
Most agent frameworks treat the full stack—planning, tool routing, context management, retries—as "the agent." But that's not what we want to optimize with RL.
ARES pushes the agent–environment boundary to the LLM interface itself. Observations are LLM requests. Actions are LLM responses. The scaffolding lives inside the environment.
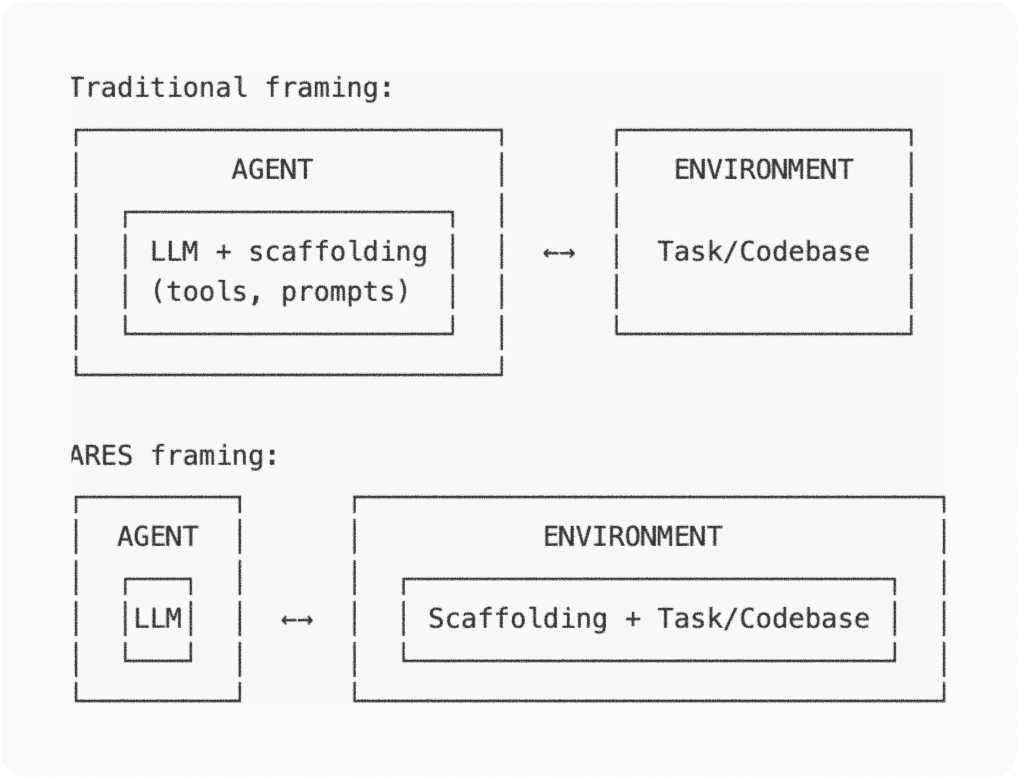
This keeps RL focused on what you actually want to improve: the model policy. You can swap agent scaffolding without touching your training code. If your goal is "train better models for agents," the model needs to be the policy.
This boundary also keeps training differentiable—you're optimizing the LLM directly, not a complex pipeline. Agent companies can plug their existing harnesses into ARES as environments, and researchers can train models specifically optimized for those harnesses. This creates a flywheel for agents companies: the more people train with your harness, the better models perform on it, differentiating you from competitors. It also means you can optimize the harness separately, measure model performance on the same harness cleanly, and do both in a massively parallel way.
This is also the right interface for interpretability research on sequential decision-making, which is how we use it internally at Martian.
2. RL-first, async-native
Unlike most LLM training frameworks, ARES is RL-first: it supports a traditional RL training loop like Gym or dm-env, not just batch-and-distill workflows. This enables a broader range of RL algorithms and faster experimentation.
A key difference from Gym or dm-env, however, is that ARES is asyncio-native. Agentic LLM workflows are dominated by I/O: remote sandboxes, tool calls, model APIs, filesystem operations. If you treat rollouts as synchronous, you either leave throughput on the table or rebuild everything around concurrency later.
This isn't just a nice-to-have. It's a 1,000x difference. Jobs we've run internally would have taken three orders of magnitude longer using synchronous infrastructure like OpenAI Gym.
We evaluate all of SWE-Bench Verified in approximately 20 minutes using Daytona for remote sandboxing.
3. Tens of thousands of open-source tasks, and counting
ARES uses the Harbor task format—a standardized specification for tasks, interfaces, scoring, and metadata developed by the Terminal-Bench team. Tasks authored for ARES remain portable across evaluation frameworks, and community benchmarks work out of the box. As harbor tasks proliferate, you can use them all inside ARES.
In partnership with Vmax, we’re releasing 1k new javascript tasks in the Harbor format.
ARES also ships with Harbor-packaged tasks including:
- SWE-Bench Verified
- Terminal-Bench 2.0
- 36 additional task sets available via Harbor
Set up RL rollouts in <10 lines of code
Here's the shape of an agent/environment loop in ARES:
import asyncio
import ares
from ares import llms
async def main():
# Define your agent (everything behind the LLM interface)
agent = llms.ChatCompletionCompatibleLLMClient(model="openai/gpt-5-mini")
# Set up your environment
# sbv-mswea = SWE-Bench Verified with Mini-SWE-Agent scaffolding
async with ares.make("sbv-mswea") as env:
ts = await env.reset()
while not ts.last():
action = await agent(ts.observation) # observation = LLM request
ts = await env.step(action) # action = LLM response
if __name__ == "__main__":
asyncio.run(main())
The environment handles sandboxing, the agent scaffold, and task setup. Your training code just sees observations and actions at the LLM boundary.
What ARES is and isn't
- Infrastructure for online RL on coding agents
- Fast parallel evaluation (SWE-Bench Verified in ~20 minutes)
- A bring-your-own-agent, bring-your-own-model design
ARES is not:
- A pretrained agent
- A training algorithm
We're actively looking to partner with teams working on training algorithms and pretrained agents to integrate them into ARES.
Get started
To start using ARES, head to the repo. Join us on Discord for announcements and to connect with other contributors.
This release is the beginning. We're working with the community on:
- New Harbor task packs and benchmarks
- More environments for tool-using agents
- Integrations with existing RL libraries and training stacks
- Scaling patterns for distributed, high-throughput rollouts
If you're training coding agents and want infrastructure that supports real online RL, we'd love to hear from you. Reach out to us at research@withmartian.com.



