

The software factory is already taking shape: bots writing code, bots reviewing it, humans dispatching. But everyone's focused on generation while the real bottleneck is quality control. Using Code Review Bench, we tracked how close AI code review is to matching human judgment across 500k+ open source PRs and 22 tools. We found two distinct usage patterns, measured how tool performance shifts depending on human involvement, and built filters that let you see results for your team's specific workflow.
In January 2026, Daniel Stenberg shut down curl's bug bounty due to AI slop, Mitchell Hashimoto restricted AI-generated code contributions from Ghostty, and Steve Ruiz closed all external PRs to tldraw. In March, Jazzband, 84 Python projects and 3,135 members, shut down entirely. Its founder called it the "slopocalypse."
Something broke in open source this year. Last year on GitHub, pull requests surged 23% and commits jumped 25%, with 80% of new developers using Copilot in their first week. Review comments grew only 0.35%. Most people are calling this a maintenance crisis, and they're not wrong. But code is being produced faster than it's being checked, and that's not a problem you solve by hiring more maintainers. This is the problem AI Code Review tools are trying to solve.
What you're looking at is the early stages of the software factory: AI handling the full development cycle, from writing code to reviewing it to shipping it, with minimal human involvement. In our dataset of 500k+ open source PRs, we're already seeing the pattern emerge. We found fully automated pipelines where bots review bots with no human in the loop, custom automation bots posing as human reviewers, and PR authors auto-acknowledging every review with scripted text.
But most of the discourse around the software factory focuses on generation: can AI write code, how fast, and how good. While people have focused on the building part of the factory, a key area has gotten less attention: the factory’s quality control. In traditional software development, a separate person reviews each pull request for bugs and correctness before it’s shipped to production. That review process is the factory's last line of defense.
So the real question isn't "can AI write code." It's: when AI reviews code, how often is it right? That gap between the AI reviewer's judgment and the human's is a literal measurement of how close the software factory is to working. When that number converges, the human can leave the loop. Until it does, you're just shipping faster, not shipping better.
Using Code Review Bench data, we analyzed this gap across 500k+ PRs and 22 tools, tracking what developers actually do after an AI tool posts a review. The results break down by tool, language, and domain, so you can see where your specific stack stands. The analysis covers merged PRs, sampled at up to 500 per tool per day, with full methodology described here.
The inspection line is mostly unattended
To measure how close AI review is to human judgment, you need PRs where a human actually engaged with the review. We looked at how often that happens.
Over half of open source bot-reviewed PRs (52.8%) see zero human activity after the bot posts its review, and 84% have no human reviewer besides the PR author. In most cases, nobody is checking whether the bot's review was correct.

ChatGPT Codex reviewed 220,000 PRs in two months alone. We analyzed ~48,000 of these merged PRs, and only 4.6% had a human reviewer besides the author. The solo-developer pattern is common across tools: 96% of Codex repos, 92% for Copilot, and 91% for Cursor have a single contributor.
We also found a growing fraction of PRs following fully automated workflows. Some show severe scripted patterns: 1.5% of PRs have 80%+ duplicate comments in a repo-bot pair, meaning someone has a script or bot auto-responding to every review. Another 6.4% show moderate patterns: individual users copy-pasting the same responses and conversations where over 80% of comments are under 50 characters with only 20–40% unique comments, suggesting low-effort or automated acknowledgments.
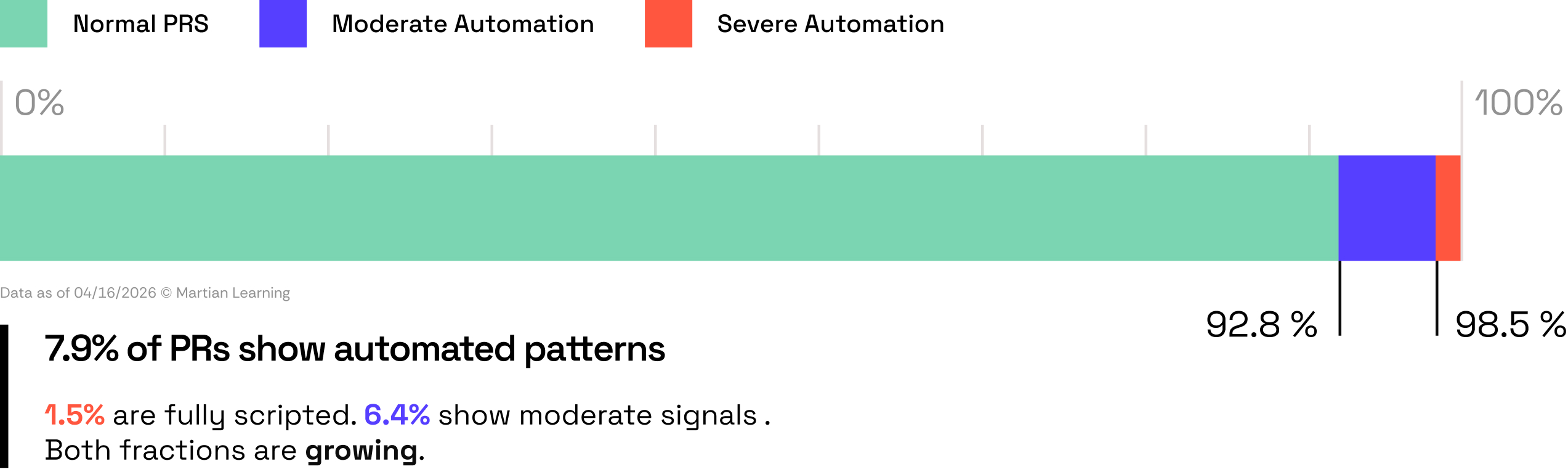
Low human engagement isn't necessarily a bad sign. In a well-functioning factory, the manager doesn't need to be on the floor for every inspection. But before you pull the manager off the floor, you need to verify that the inspector actually catches what needs catching.
Without separating these different contexts, any measurement of AI review quality is blending real signal with noise.
What happens when someone's actually checking?
Not all tools interact with humans the same way, and accounting for that matters when measuring review quality.
Some tools consistently show higher engagement, with developers replying to comments and iterating on feedback, while others are used in workflows where review happens with little to no human interaction. For example, CodeRabbit sees 60.5% engagement, and in 39% of its PRs a developer makes a follow-up commit acting on the review. ChatGPT Codex sees 33.2% engagement and 6.6% human follow-up commits.
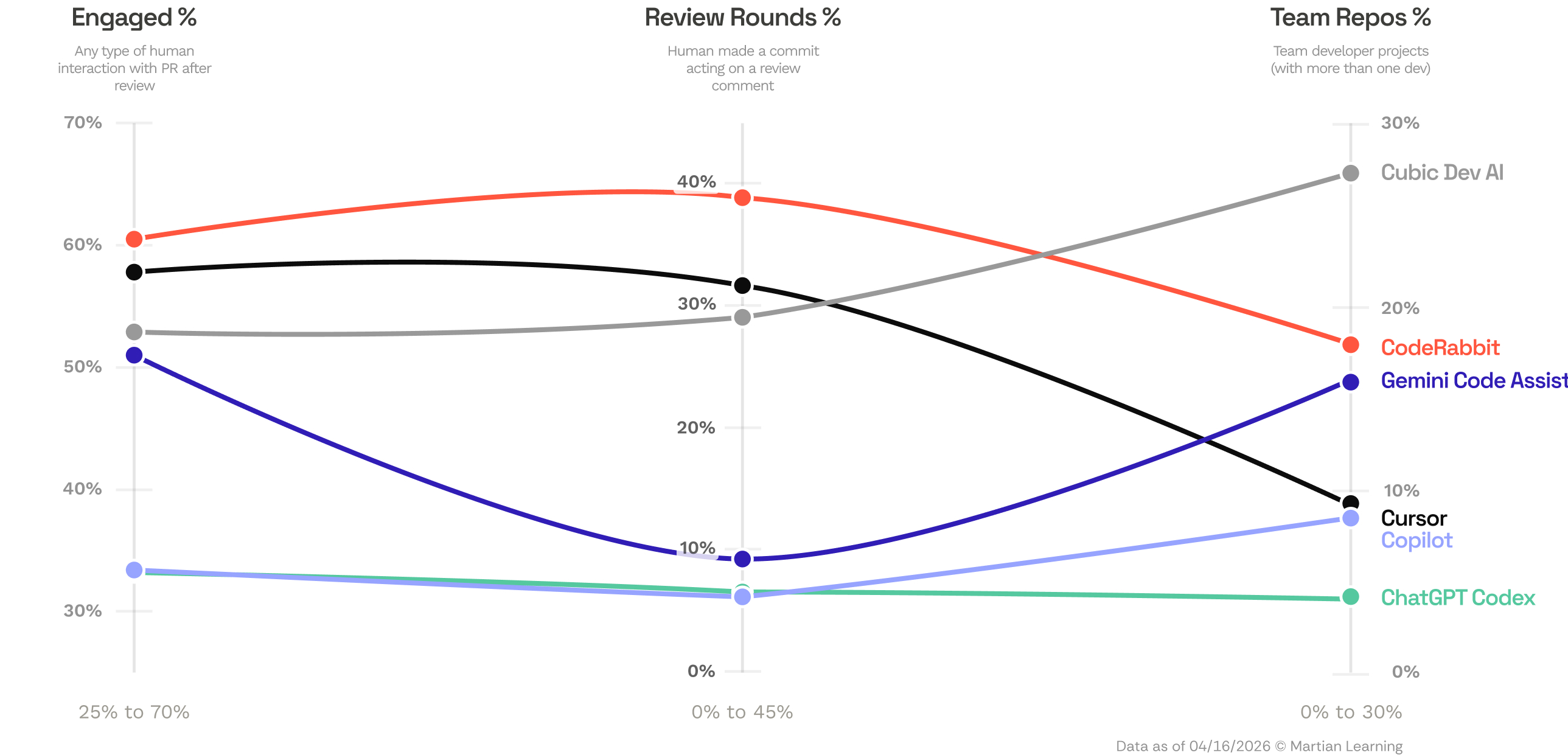
What emerges is not a single “AI code review” workflow, but two distinct usage patterns: review-centric workflows where humans actively engage with review, and more automated, agentic workflows where review happens with minimal human interaction. This could be driven by how the tools are built or how their user base has evolved, but the result is that these tools are being used in fundamentally different contexts.
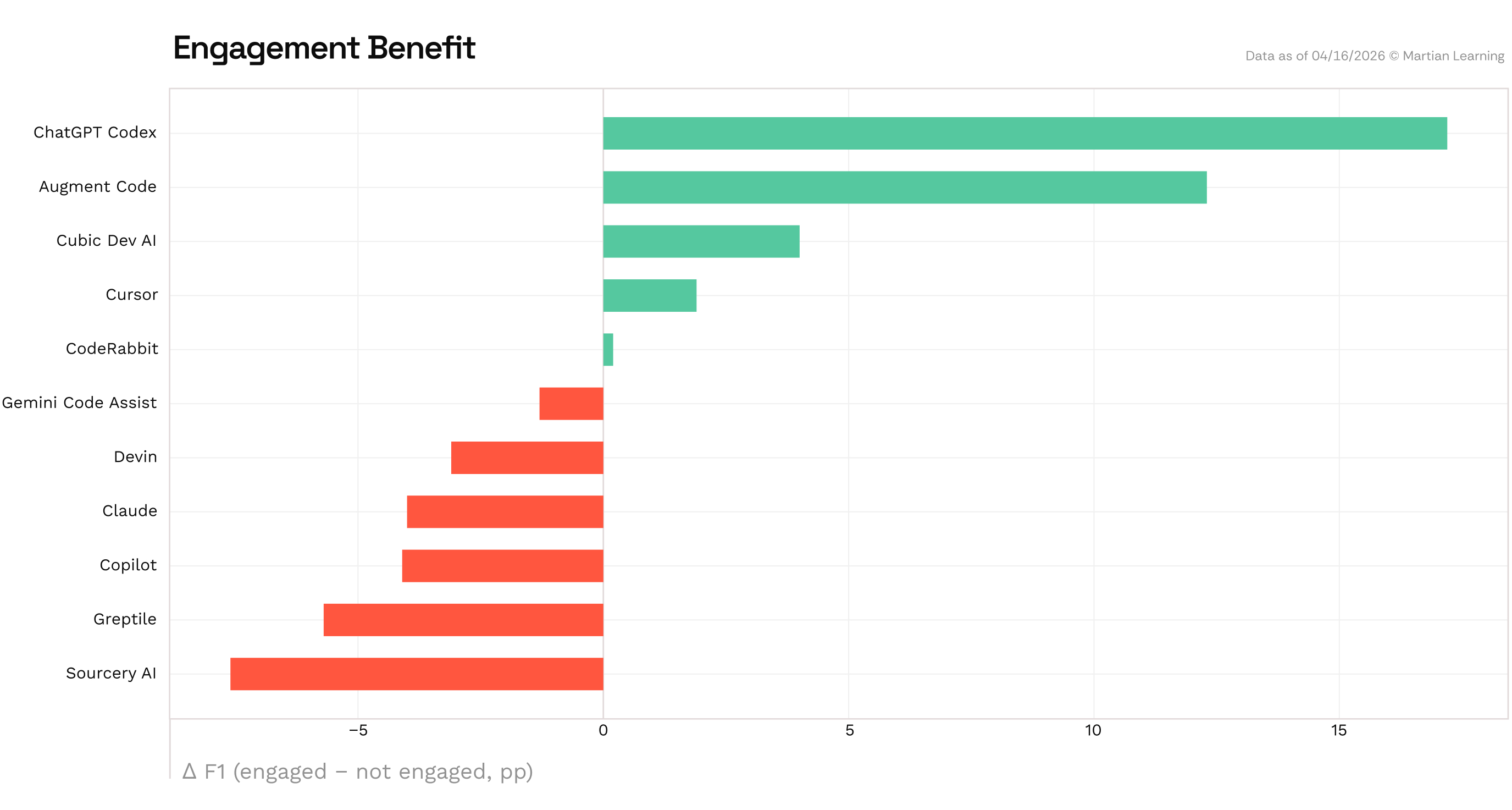
We can see this play out further when we compare tool performance on PRs where a human engaged after the review versus those where nobody did. Codex gains +17.2pp and Augment +12.3pp on engaged PRs. Claude drops -8.7pp and Sourcery -7.5pp.
What’s interesting is what this delta suggests about the human’s role in each tool’s workflow. When F1 rises with engagement, the tool tends to be noisier on PRs where nobody engages. When humans do show up, they act on the comments that matter and ignore the rest. When F1 drops with engagement, humans are surfacing real issues the tool missed: the tool is a first pass, and the human is still the reviewer. Either way, the level of human involvement changes the picture significantly, which means how you slice the data matters.
Seeing the data for your workflow
A single leaderboard score doesn't tell the full story when tools are being used in such different ways. To control for this, we built cumulative filters that progressively strip out PRs based on how humans and bots interacted with the PR. If you're evaluating tools for your team, baseline scores are nearly meaningless to you. You want to know how a tool performs on collaborative projects where someone actually reads the review.
Code Review Bench now includes these additional filters:
- Bot Authors: Do bots open PRs in your repo?
- Team Size: How many humans review your PRs? How many contributors are in your repos?
- Human Engagement: Do your engineers always act on bot review comments?
Beyond these filters, we also added a concentration cap so no single author-repo-tool combination can dominate a tool's score, and restricted the analysis to merged PRs—these are now applied to every PR shown in Code Review Bench. What remains is a smaller but higher-signal dataset that's closer to the review patterns that matter for your repos.
Where does the inspector struggle the most?
After four months of live Code Review Bench data, we also looked into understanding where AI code review still comes up short.
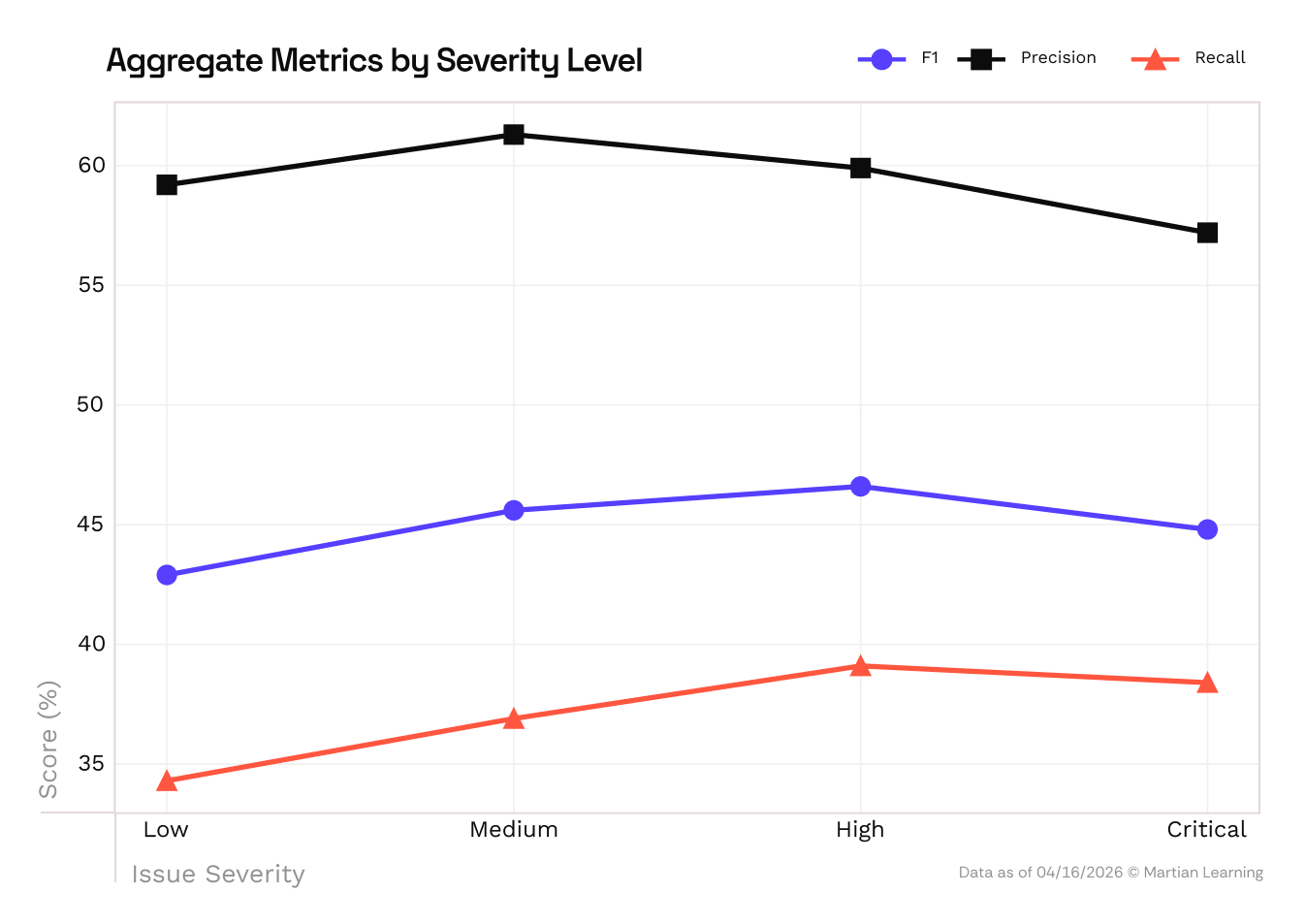
The clearest gap in current code review tools is handling larger sized PRs. In aggregate, F1 scores drops 26.7% from small PRs to large ones, and every tool degrades. The drop is driven primarily by recall: on large PRs (1k+ lines), aggregate recall falls to 30%, meaning tools miss 70% of key issues. This is an intuitive issue: the larger something is, the harder it is for any reviewer, human or AI, to catch what matters. Fullstack repos show a similar pattern: every tool scores lowest on PRs that span the full stack, while backend and infrastructure code is easier across the board. For now, this means that software factories should bias their codegen tools to create smaller, more focused PRs.

Furthermore, AI code review tools are actually better at catching critical bugs than minor ones. Recall rises with severity, meaning the more serious the issue, the more likely the tool is to flag it. Lower-severity issues are harder in a different way: they depend more on developer preference and context. One developer could treat a review comment as a useful cleanup or nitpick, another may ignore it entirely. That makes them harder to model, not because they’re less detectable, but because “correctness” is less well-defined.
Code generation tools went through a similar phase before evolving personalization features like AGENTS.md and custom skills. Code review is starting to follow, with some tools offering project-specific configurations.But adoption lags behind, partly because it's harder to experiment with what you want from a reviewer, and partly because what developers think they want doesn't always match what works: flagging every possible issue sounds helpful until the volume trains you to skim past all of them.
Moving forward: where to look at next
As the software factory is evolving, the right evaluation for each individual factory depends on how the factory is constructed and how its workers interact with it.
We see this in Code Review Bench: based on people’s individual workflows, the results can change. The “best” code review tool is unique to your situation and preferences. As we continue to develop the benchmark, we’ll continue to incorporate elements that help users better evaluate which tool is right for their use case rather than a monolithic ranking. And because the benchmark updates daily, we can track how these patterns shift over time as the tools and the workflows around them evolve.
Tell us where we should look in the data next to help us inform the next iteration of the benchmark at codereviewbench@withmartian.com.
The authors wish to thank Shriyash Upadhyay, Antia Garcia and Jacob Clyne for their contributions to this article.



